
viernes, 6 de noviembre de 2015
viernes, 14 de junio de 2013
seo
seo
Search Engine Optimization ( SEO ) es el proceso de modificar la visibilidad de un sitio web o una página web en un buscador 's "natural" o sin pagar (" orgánico ") los resultados de búsqueda . En general, cuanto antes (o de mayor rango en la página de resultados de búsqueda), y con más frecuencia un sitio aparece en la lista de resultados de búsqueda, más visitantes que van a recibir de los usuarios del motor de búsqueda. SEO se pueden orientar a los diferentes tipos de búsqueda, incluyendo búsqueda de imágenes , búsqueda local , búsqueda de vídeo , búsqueda académica ,[ 1 ] búsqueda de noticias y específicas de la industria de búsqueda vertical motores.A modo de marketing en Internet estrategia, SEO considera cómo los motores de búsqueda de trabajo, lo que la gente busca, los términos de búsqueda actuales o palabras clave tecleadas en los buscadores y motores de búsqueda, que son las preferidas por su público objetivo. Optimizar un sitio web puede implicar la edición de su contenido, HTML y asociados de codificación para aumentar su relevancia tanto a las palabras clave específicas y eliminar las barreras a las actividades de indexación de los motores de búsqueda. La promoción de un sitio para aumentar el número de backlinks o enlaces entrantes, es otra táctica SEO.
Relación con los motores de búsqueda
En 1997, los motores de búsqueda reconocen que los webmasters estaban haciendo esfuerzos para clasificar bien en los motores de búsqueda, y que algunos webmasters estaban incluso manipulando su ranking en los resultados de búsqueda por el relleno de las páginas con palabras clave excesiva o irrelevante. Los primeros motores de búsqueda, como Altavista y Infoseek , ajustar sus algoritmos en un esfuerzo por evitar que los webmasters de manipular clasificación. [ 22 ]
En 2005, se creó una conferencia, Airweb, Acusatorio recuperación de información anual sobre la Web para reunir a profesionales e investigadores interesados en la optimización de motores de búsqueda y otros temas relacionados. [ 23 ]
Las empresas que emplean técnicas demasiado agresivas pueden tener en sus sitios web de clientes prohibidos en los resultados de búsqueda. En 2005, la Wall Street Diario informó sobre una compañía, Potencia Traffic , el cual supuestamente utilizó técnicas de de alto riesgo y fracasó a revelar esos riesgos a sus clientes. [ 24 ] con conexión de cable revista de informaron de que la misma empresa demandó a blogger y la SEO Aaron Wall para la escritura de sobre la prohibición. [ 25 ] de Google Matt Cutts confirmó más tarde que Google, en efecto la prohibición de alimentación de tráfico y algunos de sus clientes. [ 26 ]
Algunos motores de búsqueda también se han acercado a la industria de SEO, y son frecuentes los patrocinadores e invitados a las conferencias de SEO, charlas y seminarios. Principales motores de búsqueda proporcionan información y directrices para ayudar con la optimización de su sitio. [ 27 ] [ 28 ] tiene un Google Sitemaps de programa para ayudar a los webmasters saber si Google está teniendo problemas de indexación de su sitio web y también proporciona datos sobre el tráfico de Google a la página web. [ 29 ] Herramientas para webmasters de Bing ofrece una manera para que los webmasters a presentar un mapa del sitio y vínculos Web, permite a los usuarios determinar la frecuencia de rastreo y seguimiento del estado del índice de páginas web.
Cómo indexadas
Los principales motores de búsqueda, como Google , Bing y Yahoo! , utilizan rastreadores para encontrar las páginas de sus resultados de búsqueda algorítmica. Las páginas que están enlazadas desde otros motores de búsqueda las páginas indexadas no tienen que ser presentadas ya que se encuentran de forma automática. Algunos motores de búsqueda, especialmente Yahoo!, operan un servicio de envío de pago que garanticen rastreo ya sea una tarifa fija o de coste por clic . [ 30 ] Este tipo de programas suelen garantizar su inclusión en la base de datos, pero no garantizan la clasificación específica dentro de los resultados de la búsqueda. [ 31 ] Dos directorios más importantes, el directorio de Yahoo y el Open Directory Project tanto requieren presentación manual y revisión editorial humanos. [ 32 ] Google ofrece Google Webmaster Tools , para lo cual un XML Sitemap alimentación puede ser creado y presentado de forma gratuita para garantizar que todas las páginas se encuentran, especialmente las páginas que no son detectables por los siguientes enlaces automáticamente. [ 33 ]
Motores de búsqueda rastreadores pueden ver una serie de diferentes factores al rastreo de un sitio. No cada página está indexada por los motores de búsqueda. Distancia de las páginas del directorio raíz de un sitio también puede ser un factor en si o no las páginas quedan arrastraban. [ 34 ]
Prevención de rastreo
Artículo principal: Robots Exclusion Standard
Para evitar contenidos no deseados en los índices de búsqueda, los webmasters pueden instruir a las arañas no para rastrear determinados archivos o directorios a través del estándar robots.txtarchivo en el directorio raíz del dominio. Además, una página se puede excluir explícitamente de la base de datos del motor de búsqueda mediante el uso de una etiqueta meta específica a los robots. Cuando un motor de búsqueda visita un sitio, el robots.txt ubicado en el directorio raíz es la primero archivo de rastreado. El archivo robots.txt es luego analizada, y dará instrucciones al robot para que las páginas no deben ser rastreado. Como un rastreador motor de búsqueda puede conservar una copia en caché de este archivo, es posible que en ocasiones rastrear páginas un webmaster no desea rastrear. Páginas normalmente impedido que se rastree como páginas de acceso específicas, tales como carros de la compra y de usuario específica del contenido, tales como los resultados de búsqueda de las búsquedas internas. En marzo de 2007, Google advirtió a los webmasters que deben evitar la indexación de los resultados de búsqueda internos porque esas páginas se consideran el spam de búsqueda. [ 35 ]
El aumento de la prominencia
Una variedad de métodos se puede aumentar la importancia de una página web en los resultados de búsqueda. entrecruzamiento entre páginas del mismo sitio web para ofrecer más enlaces a la mayoría de las páginas importantes puede mejorar su visibilidad. [ 36 ] Escritura de contenido que incluye frase de palabras clave buscados de manera frecuente, por lo que que sea relevante para una amplia variedad de consultas de búsqueda tienden a aumentar el tráfico. [ 36 ] Actualización de contenidos con el fin de mantener los motores de búsqueda arrastrándose con frecuencia puede dar más peso a un sitio. Adición de palabras clave relevantes para los metadatos de una página web, como la etiqueta del título y la descripción del meta , tenderá a mejorar la relevancia de los listados de búsqueda de un sitio, lo que aumenta el tráfico. URL normalización de las páginas web accesibles a través de varias direcciones URL, utilizando el elemento de enlace canónico [ 37 ] oa través de redirecciones 301 puede ayudar a hacer conexiones seguras a las diferentes versiones de la url todos cuentan hacia el enlace de puntuación de la popularidad de la página.

martes, 11 de junio de 2013
Las principales diferencias entre HTML5 y HTML4
Un cambio que ahora estamos viviendo es el nacimiendo de HTML5, una nueva revisión del estandard que mueve Internet y hace posble que ahora estemos interactuando (los usuarios que leen la página).
El aumento de necesidades han dado lugar a la aparición de nuevos tags, el debate sobre el uso de otros y cambios más o menos importantes pero que debemos conocer.
1. Sintaxis
El término HTML posee una sintaxis compatible con HTML4 y XHTML1 publicados en la red, pero no compatible con las características más esotéricas del SGML de HTML4.
HTML5 define detalladas reglas de parse, incluyendo un control de errores, para que esta sintaxis sea compatible con las implementaciones más populares. Los agentes de usuario seguirás las mismas reglas que para los que actualmente tienen text/html.
El otro sintaxis que se puede utilizar para HTML5 es el llamado XHTML5, que no es más que una sintaxis compatible con XML y documentos correctos en XHTML1. Los documentos servidos con esta sintaxis deben ser servidos mediante el MIME application/xml.
2. Codificación de carácteres
Al igual que sus hermanos menores, seguiremos podiendo definir el charset de nuestro documento mediante el tag <meta charset="UTF-8" > o la correspondiente versión de XML para XHTML5.
2.2. El DOCTYPE
El nuevo HTML5 requiere el elemento DOCTYPE que debe ser declarado al proncipio de la página, de esta forma nos aseguramos de que el navegador renderiza la página en modo estandard. En cambio para la versión XHTML5 este elemento es opcional debido a que XML actua de diferente manera dentro de nuestro navegador
3.1. Modelos estrictos de contenidos
HTML5 define de forma más estricta el contenido para elementos <div /> y <li />. Estos elementos ahora pueden contener contenido de elementos “block” o “inline” pero no los dos. En HTML4 esto fue considerado como un bug de la espeficación ya que permitía el uso de ambos.
Permitido:
<div> <em>…</em> <p>…</p> </div>
Otro cambio afecta al elemento <tfoot />, ahora podrá aparecer al final de la página, al igual que directamente despues del elemento <thead />.
<table border="1"> <caption>Nombre de la tabla</caption> <thead> <tr> <th scope="col">COLUMNA 1</th> <th scope="col">COLUMNA 2</th> </tr> </thead> <tbody> <tr> <td>DATOS 1</td> <td>DATOS 2</td> </tr> <tr> <td>DATOS 3</td> <td>DATOS 4</td> </tr> </tbody> <tfoot> <tr> <th scope="col">PIE 1</th> <th scope="col">PIE 2</th> </tr> </tfoot> </table> 3.2. Nuevos elementos
Los tiempos modernos requieren nuevos elementos para proporcionar una web más semántica, completa y homogenea. Para ello se han añadido una buena serie de elementos que nos permitirán encapsular más nuestro contenido.
<article /> elemento que nos permite declarar un trozo del contenido como artículo. Ideal para blogs o periódicos.
<aside /> representa un trozo de contenido que se relaciona muy levemente con el resto del contenido.
<dialog /> elemento que permite reprensetar conversaciones
<footer /> parece que me han leido la mente o quizas leyeron este post. Sección de la página para contener información sobre el autor, copyright, etc,…
<header /> representa a la sección de cabecera.
<nav /> representa la sección de la página orientada a la navegación.
<section /> elemento que indica que se trata de una sección genérica.
<audio /> y <video /> para el contenido multimedia.
<embed /> es un elemento dedicado para contenido de plugins.
<m /> representa el texto marcado.
<meter /> usado para representar medidas, por ejemplo el tamaño del disco usado…
<time /> usado para mostrar fechas y/o tiempo.
<canvas /> usado para mostrar gráficos renderizados en tiempo real, por ejemplo gráficos, juegos, etc,…
<commnad /> relacionado con los comandos que el usuario puede invocar.
<datagrid /> ideal para mostrar un arbol de datos o una tabla tabulada.
<details /> muestra información adicionar si el usuario lo demanda.
<datalist /> junto con el nuevo atributo list para los <input /> puede ser usado para crear comboboxes
<event-sources /> puede ser usado para capturar eventos enviados desde servidor.
<output /> nos indica que tipo de salida vamos producir con nuestra página.
<progress /> representa una barra de proceso de una tarea, por ejemplo descargar,…
Los elementos de entrada <input /> dispondrán de una serie de tipos (type) nuevos para indicar los diferentes tipos de elementos de entrada posibles.
datetime
datetime-local
date
month
week
time
number
range
url
La idea es que estos tipos sean poporcionados por el agente de usuario (navegador) en su interface que submitarán el formato definido al servidor.
3.3 Nuevos atributos
HTML 5 ha introducido una gran cantidad de nuevos elementos para varios elementos de los que ya disponemos en la HTML4.
media: Para conseguir una mayor consistencia con el link en los elementos <a />
ping: Especificacremos una lista separada por espacios donde produciremos un ping cuando se siga el enlace, para los elementos <area /> y <a />
target: Disponible para mejorar la consistencia con el elemento <a />.
autofocus: Destinado para indicar el elemento <input /> (no hidden), <select />, <textarea /> o <button /> que ha de coger el foco al cargar la página.
form: Atributo para <input />, <ouput />, <select /> <textarea />, <button /> y <fieldset /> que permite que se sococien con un simple formulario.
replace: atributo para <input /> <button /> y <form /> que le afectará cuando el contenido del elemento sofra algún cambio.
data: Para <form />, <select /> y <datalist />.
required: Para elementos <input /> (Excepto hidden e image) y <textarea />, indica que el campo es obligatorio.
inputmode: Atributo para <input /> y <textarea />.
disabled: Para <fieldset />, permite desactivar el fieldset completo.
autocomplete, min, max, pattern, step: Para elementos <input /> permite delimitar las posibilidades de nuestros elementos de entrada.
list: Para elementos <datalist /> y <select />.
template: Para <input /> y <button /> podrá usarse para repetir templates.
scoped: Para elemento <style />, permitirá usar hojas de estilo “scoped” ??
async: Para el elemento <script /> el ajax hecho atributo.
Atributos globales
Aparte de los ya existentes: class, dir, id, lang y title.
contenteditable: indica que se trata de una área editable.
contextmenu: Puede ser usado como punto de menú contexctual proporcionado por el usuario.
draggable: indica que se trata de un elemento draggable.
tabindex: indica la posición numérica a la que llegaremos pulsando la tecla TAB.
irrelevant: atributo que indica que el contenido no es relevante.
repeat, repeat-start, repeat-min, repeat-max: atributos referentes a las iteraciones.
3.4 Elementos Cambiados
Estos elementos de HTML5 son imcompatibles con HTML4.
El elemento <a /> sin href ahora creará un enlace al sitio.
El elemento <address /> es ahora un nuevo concepto de sección.
El elemento <b /> ahora representa un trozo de texto a ser estilizado sin ninguna importancia.
Para elementos <label /> el navegador no debe mover el foco desde la etiqueta al control a menos que el comportamiento sea estandar para el interfaz utilizado en la plataforma.
<menu /> ha sido redefinido para ser usado con los actuales menús.
El elemento <small /> ahora representa una impresión pequeña.
El elemento <strong /> definitivamente representa el enfasis puesto en trozo de nuestro texto.
3.5 Elementos eliminados
En la nueva versión, algunos de los elementos anteriormente desaprovados pasan a ser eliminados definivamente.
acronym
applet
basefont
big
center
dir
font
frame
frameset
isindex
noframes
noscript (solo en XHTML5)
s
strike
tt
u
3.6 Atributos eliminados
Al igual que los elementos los atributos tambien pasarán a mejor vida.
rev y charset en <link /> y <a />
target en <link />
nohref en <area />
profile en <head />
version en <html />
name en <map />
scheme en <meta />
archive, classid, codetype, declare y standby en <object />
valuetype en <param />
charset en <script />
summary en <table />
header, axis y abbr en <td /> y <th />
4.1. Extensión de HTMLDocument
HTML5 tambien ha modificado el elemento padre del DOM Level 2. En él encontramos una serie de mejoras y otras que finalmente se hacen estandares:
getElementsByClassName(), para seleccionar elementos por el atributo class. Ya lo comentamos hace tiempo y vimos que las diferencias a nivel de tiempo de respuesta eran más que satisfactorias.
innerHTML, aunque prácticamente se usa en todas, o casi todas, las aplicaciones web existentes, por fín será reconocido como estandar en la especificación. Además aprovechando si insercción se posibilita su uso en el elemento padre.
activeElement, hasFocus(), nos permetirá conocer el elementos activo en tiempo real y el que tenga el foco.
getSelection(), devuelve un objeto con la selección actual.
designMode y execCommand(), muy usados para editar documentos.
4.2. Extensiones del Elementos HTMLElement.
A nivel de elemento el DOM tambien ha sufrido una serie de cambios que vale la pena comentar.
getElementsByClassName(), nos permite seleccionar los hijos de cualquier objeto que contengan una clase determinada.
innerHTML, nos permite leer/modificar el contenido de un nodo (al añadir crea nodos texto con etiquetas).
classList, una implementación muy interesante para vivir con className que nos permite interactuar con las clases de los elementos, proporcionando métodos como has(), add(), remove() y toggle() con los que podremos trabajar con las clases de nuestros elementos.
relList, funciona de igual forma que classList, pero sobre los atributos rel de <a />, <area /> y <link />
viernes, 24 de mayo de 2013
Desarrollo De Software
Un proceso para el desarrollo de software, también denominado ciclo de vida del desarrollo de software es una estructura aplicada al desarrollo de un producto de software. Hay varios modelos a seguir para el establecimiento de un proceso para el desarrollo de software, cada uno de los cuales describe un enfoque diferente para diferentes actividades que tienen lugar durante el proceso. Algunos autores consideran un modelo de ciclo de vida un término más general que un determinado proceso para el desarrollo de software. Por ejemplo, hay varios procesos de desarrollo de software específicos que se ajustan a un modelo de ciclo de vida de espiral
La gran cantidad de organizaciones de desarrollo de software implementan metodologías para el proceso de desarrollo. Muchas de estas organizaciones pertenecen a la industria armamentística, que en los Estados Unidos necesita un certificado basado en su modelo de procesos para poder obtener un contrato.
El estándar internacional que regula el método de selección, implementación y monitoreo del ciclo de vida del software es ISO 12207.
Durante décadas se ha perseguido la meta de encontrar procesos reproducibles y predecibles que mejoren la productividad y la calidad. Algunas de estas soluciones intentan sistematizar o formalizar la aparentemente desorganizada tarea de desarrollar software. Otros aplican técnicas de gestión de proyectos para la creación del software. Sin una gestión del proyecto, los proyectos de software corren el riesgo de demorarse o consumir un presupuesto mayor que el planeado. Dada la cantidad de proyectos de software que no cumplen sus metas en términos de funcionalidad, costes o tiempo de entrega, una gestión de proyectos efectiva es algo que a menudo falta.
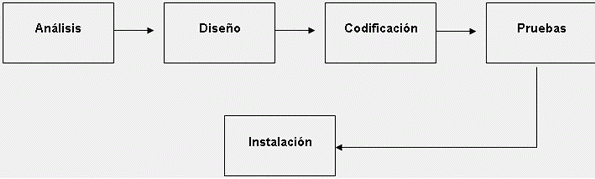
El proceso de desarrollo del software se muestra gráficamente en la parte de arriba, a continuación desarrollara una breve explicación del mismo.
El primer paso del proceso es el análisis, es aquí donde el analista se pone en contacto con la empresa para ver como esta conformada, a que se dedica, saber todas las actividades que realiza en si, conocer la empresa de manera general para posteriormente ver cuales son sus necesidades o requerimientos que la empresa tiene en ese momento para poder realizar un análisis de la misma.
Es importante saber cuales son los requerimientos que la empresa tiene por que muchas veces los sistemas se desarrollan pero no pensando en el cliente y es ahí donde el sistema no cumple o no satisface las necesidades que existen en la empresa, según los requerimientos se empieza a realizar el diagramarelacional todo debe de llevar una secuencia lógica de las actividades, todo esto se realiza de manera manual para ver como será su diseño lógico y diseño de pantallas es en este paso donde se plasma todo y queda perfectamente bien definido como va hacer la funcionalidad del sistema.
El segundo paso es el de diseño aquí entran todo el diseño del sistema es decir las pantallas, base de datos, todo esto debe de cumplir con ciertos estándares los cuales se toman en cuenta para poder desarrollar el diseño con calidad y así poder ofrecer un diseño amigable en cuestión de colores, tamaños de botones, cajas de texto, etc.
El tercer paso es la codificación es aquí donde se desarrolla todo el código del sistema por parte del programador esto se hace ya dependiendo de cada programador ya que cada programador tiene sus bases o formas para realizarlo pero en si deben todos llegar al mismo objetivo de ofrecerle funcionalidad al sistema siempre y cuando apegando se a las especificaciones del cliente.
El cuarto paso son las pruebas, es donde al sistema se pone a prueba como su palabra lo dice para así poder saber cuales son los posibles errores que se están generando del sistema y con ello mejorarlo para eliminar todos los errores que se puedan presentar por que un programa con menor errores mayor calidad puede llegar a tener.
El quinto y último paso es la instalación una vez realizado las pruebas correspondientes al sistema y haberlo corregido totalmente se procede a la instalación del mismo ya en la empresa para su uso correspondiente, todo con la finalidad de que los procesos se realicen de una manera más eficiente eliminando costos, tiempo y esfuerzo dentro de la organización.
Para aplicar la mejora continua a todo lo anterior es necesario aplicar ciertos pruebas las cuales deberán de probar cada etapa del desarrollo delsoftware dichas pruebas se deben de realizar de forma paralela y de forma continua probando la unidad del programa, la integración del diseño físico, probando el sistema en cuestión al diseño lógico y por ultimo prueba de aceptación esta se realiza en base a los requerimientos que se obtuvieron anteriormente, este es un proceso de prueba sencilla y muy utilizada.
Etapas de desarrollo de software
- Requisitos
- Análisis
- Diseño
- Codificación
- pruebas
- implementacion
- Mantenimiento
| ETAPAS DE DESARROLLO DE PROGRAMACIÓN |
| Requisitos | Cuestionar al cliente para saber que es lo que pide |
| Análisis | Pensar como podria ir estructurada la parte del codigo |
| Diseño | Que tipo de interface le gustaria al usuario |
| Codificación | La parte del desarrollo del codigo |
| Pruebas | Saber nuestros errores |
| Implementacion | Introducir algun otro tipo de funcion |
| Mantenimiento | Estar checando si el software funciona correctamente |
domingo, 19 de mayo de 2013
Problemas
1.- Desarrollar el sistema de administración escolar de la UTSOE
Problemas del Administrador
Problemas del Administrador
- Al momento de poner el costo del software.
- Al momento de hacer los análisis de requerimientos al no explicarse bien.
- No cuente con alguna licencia para un lenguaje de programación.
- Que el software no realice la función que el administrador pidió.
- Que no de el tiempo necesario para realizar el software.
Problemas del desarrollador
- No cuente con los conocimientos necesarios
- No tenga el equipo Requerido para trabajar
- El software no se entregue en tiempo y forma
- No tener una área de trabajo adecuada
- Problema al comunicarse con el administrador
Los problemas dichos anteriormente son de clasificación: complejos. rompecabezas y dilemas ya que en cada uno de ellos podemos encontrar diferentes caminos para solucionarlos y en otros nos tendríamos que poner a pensar para poder solucionarlos
2.-Control de inventario de UNIVEX
Problemas del administrador
- El administrador no cuenta con una licencia de lenguaje de programación.
- El administrador no sabe redactarse en el análisis de requerimientos.
- Que el software no realice las funciones que el administrador pidió.
- El administrador no esta de acuerdo en el costo del software.
- El administrador quiere el software demasiado rápido para entregar.
Problemas del desarrollador.
- El desarrollador cuenta con los conocimientos necesarios.
- No cuente con una área de trabajo para el.
- El administrador no este de acuerdo con el costo del software.
- El software no se entregue en tiempo y forma indicada.
- No tener buena comunicación con el administrador.
Estos problemas son de clasificación: Complejos, Dilemas y Rompecabezas, porque cada uno de ellos puede tener varios tipos de soluciones y algunos otros nos tenemos que poner a pensar bien en su solucion.
lunes, 13 de mayo de 2013
QUIEN SOY??????
AUTOBIOGRAFIA:
Yo soy Raúl nací el 2 de junio de 1993 en Salamanca Gto. ahora tengo una edad de 19 años, estudie en la primaria andes delgado cerca de mi colonia.
Después ingrese ala secundaria albino garcía en donde curse 3 años,cuando termine la secundaria ingrese al CECYTEG plantel Salamanca en el que curse durante 3 años la carrera de técnico en mecatronica y por lo cual pude obtener mi titulo de técnico en mecatronica.
Actualmente estudio en la Universidad Tecnológica del Suroeste de Guanajuato en la cual estoy cursando la carrera de tecnologías de la información y comunicación, la cual espero terminar dentro de 3 años.
METAS PERSONALES:
Terminar mi carrera en TSU e Ingeniería
METAS PROFESIONALES:
Lograr establecerme en una empresa o ser mi propio jefe
HABILIDADES Y PENSAMIENTOS:
Me considero bueno en el basquetbol, vídeo juegos, ajedrez, dibujando, jugando y utilizando la computadora.
¿QUE HARÍA SI?
*FUERA MUY RICO:
Me aria socio de una empresa importante que tenga que ver con la tecnología
Haria una donación para la creación e investigación de nueva tecnología en México
*SI HUBIERA UN SOLO LUGAR EN EL MUNDO AL QUE PUDIERA IR CUAL SERIA Y PORQUE.
Yo iría a Japón porque son los que están mas avanzados en la tecnología.
*QUE LUGAR DEL MUNDO NO VISITARÍA Y PORQUE.
No visitaría el lugar que estuviera en guerra porque seria muy peligroso y mi vida estaría enserio en peligro y seria muy triste estar ahí.
Yo soy Raúl nací el 2 de junio de 1993 en Salamanca Gto. ahora tengo una edad de 19 años, estudie en la primaria andes delgado cerca de mi colonia.
Después ingrese ala secundaria albino garcía en donde curse 3 años,cuando termine la secundaria ingrese al CECYTEG plantel Salamanca en el que curse durante 3 años la carrera de técnico en mecatronica y por lo cual pude obtener mi titulo de técnico en mecatronica.
Actualmente estudio en la Universidad Tecnológica del Suroeste de Guanajuato en la cual estoy cursando la carrera de tecnologías de la información y comunicación, la cual espero terminar dentro de 3 años.
METAS PERSONALES:
Terminar mi carrera en TSU e Ingeniería
METAS PROFESIONALES:
Lograr establecerme en una empresa o ser mi propio jefe
HABILIDADES Y PENSAMIENTOS:
Me considero bueno en el basquetbol, vídeo juegos, ajedrez, dibujando, jugando y utilizando la computadora.
¿QUE HARÍA SI?
*FUERA MUY RICO:
Me aria socio de una empresa importante que tenga que ver con la tecnología
Haria una donación para la creación e investigación de nueva tecnología en México
*SI HUBIERA UN SOLO LUGAR EN EL MUNDO AL QUE PUDIERA IR CUAL SERIA Y PORQUE.
Yo iría a Japón porque son los que están mas avanzados en la tecnología.
*QUE LUGAR DEL MUNDO NO VISITARÍA Y PORQUE.
No visitaría el lugar que estuviera en guerra porque seria muy peligroso y mi vida estaría enserio en peligro y seria muy triste estar ahí.
Suscribirse a:
Entradas (Atom)